实验4指导 - Linux综合-——搭建Hadoop系统运行WordCount
学习目标
- 系统安全
- 使用ssh scp 等命令
- 复习环境变量配置、解压、压缩配置
- 搭建Hadoop环境,运行MapReduce程序
- 学习目标
- 报告正文80分,习题20分
*提交时间 >- 网络工程231-234班,2025年5月25日(第12周 周日)23:00
*补交时间(补交满分80计算)
*提交方法
- 电子版:学习通平台上提交
- 打印版:2025年5月26-27日(第13周 周一、周二)(网络231-234)
环境准备
- 软件准备
hadoop下载:hadoop-2.8.3.tar.gz
jdk下载jdk-8u171-linux-x64.tar.gz
hadoop配置文件 样例hadoopcfg.tar.gz
测试输入文件theoldmanandthesea.txt
- 硬件准备
- 两台以上计算机(使用虚拟机),一台作为主节点,其他作为从节点。
- 主节点内存4G 2cpu 从节点 2G 1cpu 从节点设置文本方式
- 所有计算机在一个局域网内,并且可以连通
- 关闭防火墙
- 背景知识
- hadoop采用主从架构,一个主节点,负责任务分配。多个从节点,负责任务执行。
- hadoop使用ssh命令启动集群中,在集群上启动需要的进程。因此需要配置ssh无密码登录,使主节点可以不使用密码登录到各从节点。
- 配置时主从节点使用的配置文件是一致的,因此我们先配置好主节点,再将配置文件拷到各个从节点的方法配置
- Hadoop2.0组成 •HDFS ——分布式文件系统 •MapReduce——分布式编程模型 •Core——通用组件 •YARN——资源管理与调度框架
- 虚拟机1 的hostname为master
- 虚拟机2的hostname为slave
主机 IP hostname 配置 虚拟机1 192.168.123.181 master 1核2线程 4G内存 虚拟机2 192.168.123.182 slave 1核2线程 2G内存
任务1:基本配置(主从节点皆需配置)
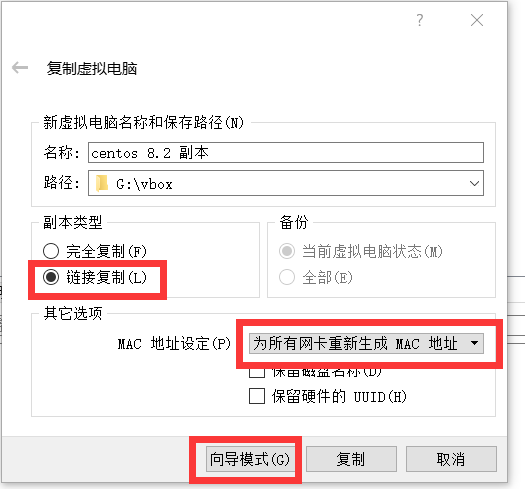
- 克隆虚拟机
- 注意选择专家模式,选择链接复制、为所有网卡重新生成MAC
- 标识好两个虚拟机,哪台作为主节点,哪台作为从节点
- 启动从节点,并设置从节点为文本模式启动
- 开启两个虚拟机
- 设置两个虚拟机的ip地址(两个虚拟机ip地址不同)
使用nmcli、nmtui等工具设置虚拟机的IP地址
- 设置两个虚拟机的域名(两个虚拟机域名不同)
- nmtui
- 关闭防火墙
- systemctl stop firewalld
- systemctl disable firewalld
- 配置域名解析
- 修改/etc/hosts文件
修改/etc/hosts后,退出root用户,使用stu用户继续后面操作
任务2:SSH密钥配置
- 在主、从节点分别设置密钥
- ssh-keygen -t rsa
- 然后连续按回车键直到命令执行结束
在主节点以stu用户输入: (第一次连接时,提示是否继续,需要输入yes ,接着需要输入密码) 结果截图
ssh-copy-id slave
ssh-copy-id master
验证成功: 以stu用户在主节点分别输入以下命令,可以无密码登录 结果截图
ssh localhost
ssh master
任务3:hadoop安装、jdk安装
hadoop下载:hadoop-2.8.3.tar.gz jdk下载jdk-8u171-linux-x64.tar.gz
结果截图 tar -xzvf jdk-8u171-linux-x64.tar.gz
tar -xzvf hadoop-2.8.3.tar.gz
任务4: 环境变量配置(主从节点皆需配置)
- 修改.bashrc文件,添加JAVA_HOME、HADOOP_HOME、PATH变量 结果截图
- 修改.bashrc文件后,需要重启命令行配置才可生效,或输入以下命令
source .bashrc
任务5:修改hadoop配置文件
- hadoop需要修改etc/hadoop/的几个配置文件,分别为mapred-site.xml、core-site.xml、hdfs-site.xml、yarn-site.xml、slaves几个文件。
- 配置文件样例hadoopcfg.tar.gz
- 所有xml文件中,修改master出现处为主节点域名
- core-site.xml 中 修改 hadoop.tmp.dir 路径
- slaves文件中,添加所有从节点的域名,每个节点一行 (这里添加master和slave)
- 修改sbin/start-all.sh 添加
"${HADOOP_HOME}"/sbin/mr-jobhistory-daemon.sh start historyserver
- 修改sbin/stop-all.sh 添加
"${HADOOP_HOME}"/sbin/mr-jobhistory-daemon.sh stop historyserver
任务6:复制文件到从节点
- 复制hadoop、jdk安装包到从节点
scp /home/stu/jdk-8u171-linux-x64.tar.gz slave:/home/stu/ scp /home/stu/hadoop-2.8.3.tar.gz slave:/home/stu/ - 解压hadoop、jdk安装包
ssh slave "tar -xzvf hadoop-2.8.3.tar.gz" ssh slave "tar -xzvf jdk-8u171-linux-x64.tar.gz" - 验证安装 登录从节点,查看两个目录已经解压好
- 复制配置文件
scp /home/stu/hadoop-2.8.3/etc/hadoop/* slave:/home/stu/hadoop-2.8.3/etc/hadoop/
任务7:格式化hadoop文件系统与首次启动
- 格式化hadoop文件系统 结果截图
bin/hadoop namenode -format - 启动hadoop
sbin/start-all.sh - 验证安装,在主、从节点分别运行命令jps
主节点应有以下进程 结果截图
从节点应有以下进程 结果截图NameNode NodeManager DataNode ResourceManager SecondaryNameNodeNodeManager DataNode 建立hdfs必要文件夹(首次建立hdfs后需要创建)
bin/hadoop dfs -mkdir /user bin/hadoop dfs -mkdir /user/stu #stu为用户名任务8:验证安装,运行WordCount程序
- 上传文件到hdfs
bin/hadoop dfs -put ~/theoldmanandthesea.txt 学生姓名1.txt - 查看文件 结果截图
bin/hadoop dfs -ls - 启动wordcount作业 结果截图
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.3.jar wordcount 学生姓名1.txt 学生姓名2.txt - 下载作业运行结果
bin/hadoop dfs -get 学生姓名2.txt ~/学生姓名2.txt - 查看结果 结果截图
cat ~/学生姓名2/part-r-00000 - 浏览器打开如下网址,可以看到界面 结果截图
http://master:8088/
习题
如果主节点域名为 学生姓名1 ,从节点域名为 学生姓名2 ,需要修改哪些地方?